Understanding the Vulnerability Disclosure to Detection Lifecycle
Vulnerability management sits at the centre of most security programmes. Compliance frameworks mandate it, the NCSC places it at the core of baseline cyber hygiene, and Cyber Essentials requires high-risk vulnerabilities to be addressed promptly. But even organisations taking this seriously face a gap in how vulnerability scanning actually works, and what it cannot do. Understanding what happens between a vulnerability becoming public and that capability arriving in your scan tool changes how you think about the problem.
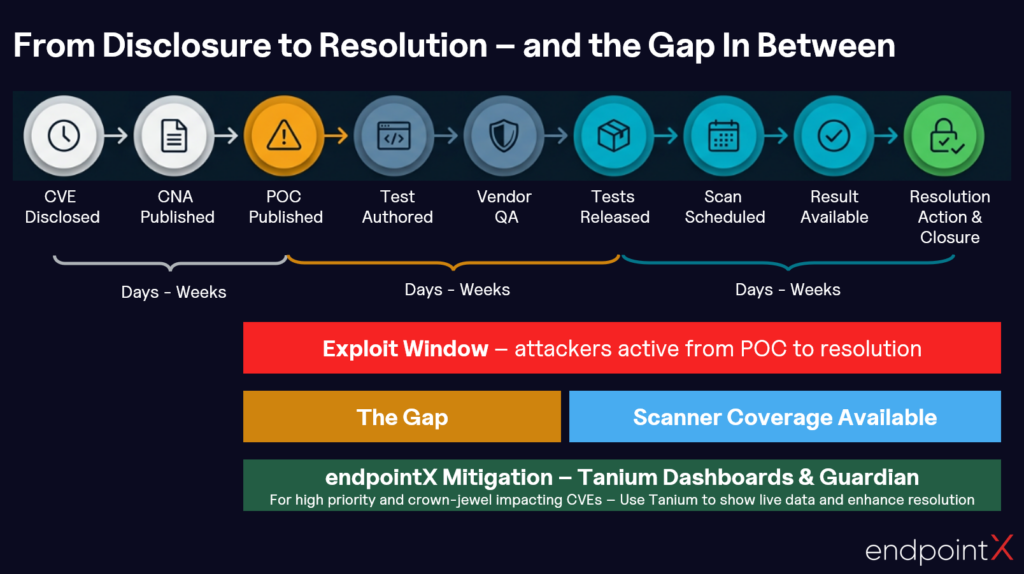
Stage 1: CVE Disclosure
When a vulnerability is discovered, it eventually receives a CVE identifier. MITRE oversees the CVE programme, but many of the largest vendors, including Microsoft, Google, Red Hat, Cisco, and Oracle, are authorised CVE Numbering Authorities (CNAs). They self-assign CVE IDs and publish their own security advisories, with affected version ranges, severity scores, and remediation guidance, at the same time as releasing patches.
The National Vulnerability Database (NVD), managed by NIST, enriches CVEs with additional metadata such as CVSS scoring and CPE identifiers. But scanner researchers at Tanium, Tenable, Qualys, Rapid7, and elsewhere primarily work from vendor advisories directly, not from NVD. Tenable’s own research found an average delay of 117 days between initial vulnerability discovery and full NVD enrichment across major software vendors. The 2024 backlog, in which NIST acknowledged thousands of entries sitting unprocessed for months, made a pre-existing gap visible to everyone who had not already adapted around it.
Stage 2: Proof of Concept
A proof of concept turns an abstract CVE into something actionable, and determines how quickly both sides of this equation can move.
A PoC can come from the discovering researcher, from independent researchers reverse-engineering a vendor’s patch, or from exploit kit developers. Many vendors publish advisories that confirm a fix exists and list affected versions, but provide minimal technical detail about how the vulnerability actually works. Some patch silently with no advisory at all. Scanner researchers work from the same public advisory information as the rest of the security community. When an advisory says only “remote code execution: update to version X” without explaining the mechanism, the information needed to write anything beyond a basic version check simply is not publicly available.
Because patch diffs are accessible the moment a fix ships, researchers and attackers alike can derive the vulnerability mechanics from the fix itself. For an attacker, that is enough: they need something that works once, on a specific target. For a scanner researcher, the bar is different. A detection needs to work reliably across thousands of endpoints in varied configurations, without false positives or false negatives, and then pass QA before release. That is a materially harder problem from the same starting point, and it is where the additional time actually goes.
Stage 3: Test Authoring
The same constraint applies equally to every scanning platform: Tenable Nessus, Qualys VMDR, Rapid7 InsightVM, Tanium Comply, or anything else. A security researcher must write a detection. Not an exploit. A detection: a test that queries an endpoint for evidence the vulnerability is present.
For version-based checks, which are the most common type, the vendor advisory alone is usually sufficient. If a vulnerability affects all versions below a patched release, the test checks the installed version and nothing more. These can be authored within hours of publication.
Network-based probes, configuration-state checks, and anything where detection requires understanding how the vulnerability triggers genuinely need a PoC or detailed technical analysis. You cannot write a reliable test for something you cannot reproduce or fully characterise. Without that public detail, the researcher works from patch diffs and bulletin fragments. That takes days to weeks for actively investigated CVEs, and potentially months or never for lower-priority ones.
No scanning vendor gets around this. It varies by vulnerability complexity, not by platform.
Log4Shell (CVE-2021-44228, disclosed 10 December 2021) illustrates both ends of the spectrum. Initial version-based detection arrived within days of disclosure. Full coverage across all affected configurations took considerably longer, because the vulnerability lived inside a logging library embedded across thousands of downstream products, and confirming reliable detection at that scale required substantially more work.
Stage 4: QA, Validation, and Release
Once authored, a test goes through quality assurance: validation against patched and unpatched systems, false-positive testing, and peer review. A poorly written plugin that flags healthy systems, or silently misses what it is supposed to find, damages prioritisation and erodes trust in the programme. It also adds time.
Stage 5: Scan Scheduling, Execution, and Results
Most organisations run credentialed scans on a weekly, fortnightly, or monthly cycle. For high-profile CVEs, major platforms can release plugins within days, and organisations with frequent scans can have a result within a week or two. For the long tail of CVEs, it can be weeks, months, or never. The scan scheduling gap applies universally: a plugin only produces results when the next scan runs.
At endpointX – we primarily schedule our vulnerability scans with Tanium, and its agent based scans can be run on a frequent basis (every few days) without compromising resource utilisation, meaning this window can be shorter than average for detection of vulnerabilities.
Unit 42 found in their 2022 research that threat actors began scanning for newly disclosed vulnerabilities within 15 minutes of announcement. By the time a plugin has been authored, QA’d, released, and picked up by a scheduled scan, attackers have often had weeks of unobstructed opportunity.
And critically, a result is not a resolution. Detection tells you the vulnerability is present. It does not fix it. The Ponemon Institute’s 2019 research found organisations took an average of 102 days to patch critical vulnerabilities after discovery, with only 13% able to do so within 14 days. The exposure window runs from when attackers can act to when the vulnerability is remediated and resolved. Vulnerability Resolved is the only point at which exposure genuinely ends.
AI Is Making The Gap Asymmetric
Large language models can parse CVE descriptions, analyse patch diffs, and generate exploit scaffolding at a level that would have taken a skilled researcher days to reach independently just a few years ago. Offensive tooling incorporating AI has moved from research papers into operational use. The time and skill required to weaponise a newly disclosed vulnerability have dropped materially.
Researchers use AI too: parsing advisories, analysing patch diffs, scaffolding detection logic. But the bottleneck was never the speed of analysis. A detection plugin must work correctly across every configuration it will encounter in the wild, produce no false positives, and miss nothing it should catch. That quality bar does not move because the drafting was faster. A plugin that fires incorrectly at scale does more damage to a vulnerability programme than no plugin at all, and getting it right still takes the time it takes.
Mandiant’s M-Trends 2025 report found the average time to weaponise a disclosed vulnerability has collapsed to five days, with 56 percent weaponised within the first month of disclosure. Exploits remained the most common initial infection vector for the fifth consecutive year, appearing in 33 percent of incidents investigated. The detection pipeline has not compressed on the same timescale. That is the asymmetry.
Patching Is the Other Half, and It Should Come First
Scanning is often treated as the driver of patching decisions: something is flagged, triaged, and scheduled for remediation. That has the order of operations backwards.
Patching should happen proactively, as a matter of operational discipline, not reactively as a consequence of a scan result.
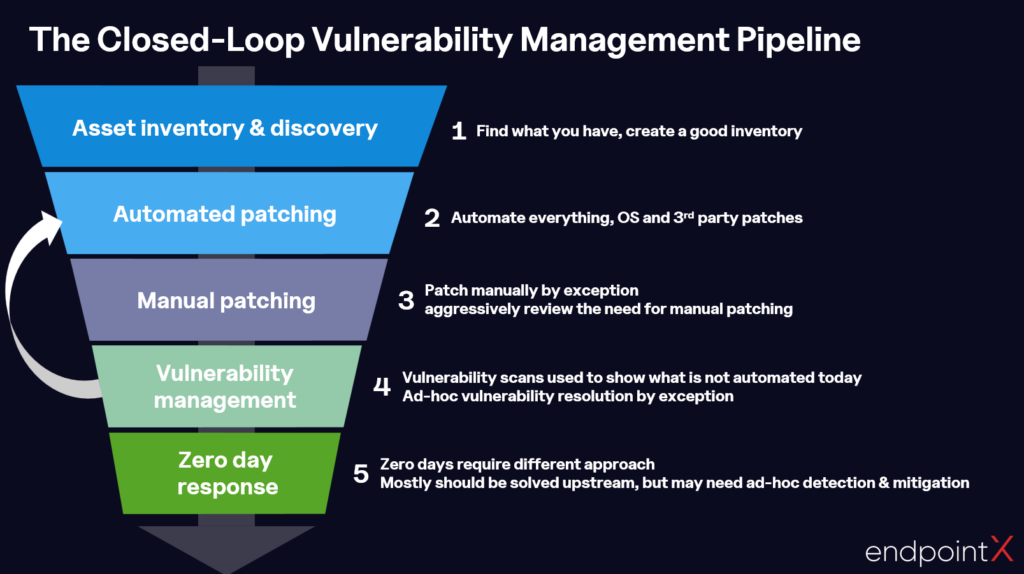
Auto-patching, covering OS patches and third-party software updates, should be the default state for any managed estate. When Patch Tuesday arrives, or a vendor ships a critical fix, IT teams should be applying it as a matter of process. If a widely-publicised critical patch is only being applied because a scan flagged it, the process has already failed.
CISA’s Known Exploited Vulnerabilities catalog documents hundreds of CVEs confirmed as actively exploited in the wild, many before patches were widely deployed. Organisations treating scanning as the trigger for patching are already behind.
Vulnerability scanning then serves a more targeted purpose: highlighting exceptions. What has not been patched? What fell outside scope? Where did auto-patching fail or not reach? Scanning becomes a verification and escalation mechanism, not the trigger for patching.
Manual patching by exception should be reviewed aggressively. Every item there represents a process not yet automated, and reducing that list should be an ongoing objective. Zero-day response is a separate track entirely: it requires detection and mitigation that can operate before a patch exists.
Beyond CVEs: The Environmental Risks Scanners Cannot Reach
Traditional scanning works within a well-defined model: CVE disclosed, test authored, scan runs, result returned. It has no answer for a growing class of risk that operates entirely outside it.
Supply chain compromises, trojanised software distributions, and malicious components embedded in legitimate tools do not produce CVEs. A scanner looking for known weaknesses in known products will find nothing, because by its own definition there is nothing to find.
The supply chain attack on Notepad++ in 2025 illustrated this directly. Attackers compromised the project’s hosting infrastructure and hijacked its update mechanism, silently delivering malicious executables to users at targeted organisations. The attack ran undetected for months. No CVE was assigned to the compromise itself. A credentialed vulnerability scan would have returned nothing of note.
The SolarWinds attack in 2020 embedded a backdoor in a legitimate software update distributed to thousands of organisations globally. The XZ Utils backdoor, discovered in early 2024, was deliberately introduced into a widely shipped compression library. In each case, the software appeared present, functional, and legitimate. The threat was in what had been quietly added to it.
Scanning has no mechanism for assessing this class of risk. What these situations require is a real-time profile of the estate: unexpected installations, binaries that do not match expected hashes, software sourced from unrecognised locations, tools present where they should not be.
That is a second distinct reason why Tanium’s live data matters at endpointX. When a supply chain compromise is reported, we can query the estate for specific software versions, installation paths, file signatures, or binary attributes immediately, with no plugin and no scan window. Scanning answers: which systems have known vulnerable software? Live data answers: what is actually installed, and does it match what should be there? Both questions matter.
The Gap, and How We Address It at endpointX
Even with strong auto-patching in place, there is a period between a vulnerability being disclosed and any scanner being able to detect it with confidence. That gap is real, and it is the same regardless of which scanning platform you run.
At endpointX, we use Tanium to address this for the situations that warrant it: not as a replacement for the scanning pipeline, but as a targeted intervention. Tenable, Qualys, Rapid7, and Tanium Comply all face the same plugin authoring constraint. For everything routine, the standard pipeline does the job.
The process is deliberate and manual, applied only when a CVE is actively being exploited, carries significant severity, or could directly affect crown-jewel assets. Research from Kenna Security and the Cyentia Institute found roughly one in twenty published CVEs is ever observed being exploited in the wild, and which five percent will matter is rarely obvious at disclosure. Applying this layer to everything would quickly erode the signal-to-noise ratio that makes it useful.
Immediate Live Querying for High-Profile CVEs
When a high-profile vulnerability drops with credible exploitation evidence behind it, we build targeted Tanium queries using live sensor data to immediately assess exposure across the estate. If a CVE affects a specific application version, we query every managed endpoint for it in real time. No plugin, no maintenance window, no waiting. Results come back within minutes, giving security teams an immediate answer to the question that matters most in the hours after a critical disclosure: are we exposed?
Tanium Guardian
Tanium’s Guardian facility tracks exposure to specific vulnerabilities in near-real time using continuous endpoint data collection, rather than a compliance scan cycle. For high-priority CVEs, it provides a persistent, live view of which endpoints are affected, updated as endpoints check in rather than as a point-in-time snapshot. Together, live queries and Guardian give actionable visibility from the moment a CVE is disclosed, long before any scanning platform has coverage.
Bringing It Together
Scanning platforms (Tanium Comply, Tenable, Qualys, Rapid7) are mature and worth running well. They all share the same structural constraint: a researcher has to author a test before any tool can find anything. That is not going away. What they compete on is the speed and quality of that authoring, and the breadth of coverage over time.
At endpointX, we build processes that account for the gap that constraint creates: disciplined auto-patching to minimise exposure windows, structured vulnerability scanning as a verification mechanism, and live Tanium querying and Guardian for immediate visibility on high-priority disclosures before the scanning pipeline catches up.
Each part does something the others cannot. Together, they cover the full lifecycle from disclosure to resolution, including the gap in the middle that most scanning-led programmes leave unaddressed. A scan result tells you where you stand. Getting to resolved is the objective.